Kaggleの回帰問題のチュートリアルである、住宅価格の予測「House Prices: Advanced Regression Techniques」に挑戦しました。
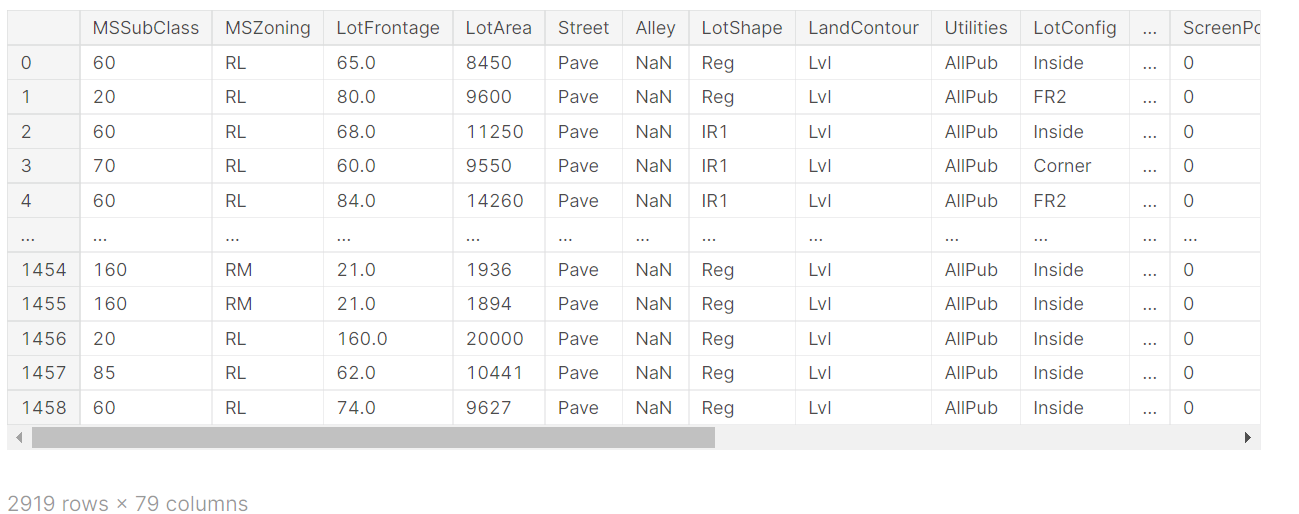
このチュートリアルの目的は、与えられた79の説明変数(敷地面積や天井の高さ等の住宅データ)をもとにSalePrice(住宅の販売価格)を予測することです。
ライブラリの準備
まず今回使用するライブラリをインポートします。
学習データの読み込み
# 訓練データをデータフレームに読み込む
train = pd.read_csv(
"../input/house-prices-advanced-regression-techniques/train.csv")
# テストデータをデータフレームに読み込む
test = pd.read_csv(
"../input/house-prices-advanced-regression-techniques/test.csv")
print('train shape:', train.shape) # 訓練データの形状を出力
print('test shape:', test.shape) # テストデータの形状を出力
出力結果
train shape: (1460, 81)
test shape: (1459, 80)
訓練データには1460レコード、テストデータには1459レコードのデータが収録されています。訓練データのカラム数は81ですが、テストデータでは予測に使用する'SalePrice'がないので、カラム数は80となっています。訓練データの情報をDataFrame.info()メソッドで出力してみます。
# 訓練データの情報を出力 train.info()
出力結果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1460 entries, 0 to 1459
Data columns (total 81 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 1460 non-null int64
1 MSSubClass 1460 non-null int64
2 MSZoning 1460 non-null object
3 LotFrontage 1201 non-null float64
4 LotArea 1460 non-null int64
5 Street 1460 non-null object
6 Alley 91 non-null object
7 LotShape 1460 non-null object
8 LandContour 1460 non-null object
9 Utilities 1460 non-null object
10 LotConfig 1460 non-null object
11 LandSlope 1460 non-null object
12 Neighborhood 1460 non-null object
13 Condition1 1460 non-null object
14 Condition2 1460 non-null object
15 BldgType 1460 non-null object
16 HouseStyle 1460 non-null object
17 OverallQual 1460 non-null int64
18 OverallCond 1460 non-null int64
19 YearBuilt 1460 non-null int64
20 YearRemodAdd 1460 non-null int64
21 RoofStyle 1460 non-null object
22 RoofMatl 1460 non-null object
23 Exterior1st 1460 non-null object
24 Exterior2nd 1460 non-null object
25 MasVnrType 1452 non-null object
26 MasVnrArea 1452 non-null float64
27 ExterQual 1460 non-null object
28 ExterCond 1460 non-null object
29 Foundation 1460 non-null object
30 BsmtQual 1423 non-null object
31 BsmtCond 1423 non-null object
32 BsmtExposure 1422 non-null object
33 BsmtFinType1 1423 non-null object
34 BsmtFinSF1 1460 non-null int64
35 BsmtFinType2 1422 non-null object
36 BsmtFinSF2 1460 non-null int64
37 BsmtUnfSF 1460 non-null int64
38 TotalBsmtSF 1460 non-null int64
39 Heating 1460 non-null object
40 HeatingQC 1460 non-null object
41 CentralAir 1460 non-null object
42 Electrical 1459 non-null object
43 1stFlrSF 1460 non-null int64
44 2ndFlrSF 1460 non-null int64
45 LowQualFinSF 1460 non-null int64
46 GrLivArea 1460 non-null int64
47 BsmtFullBath 1460 non-null int64
48 BsmtHalfBath 1460 non-null int64
49 FullBath 1460 non-null int64
50 HalfBath 1460 non-null int64
51 BedroomAbvGr 1460 non-null int64
52 KitchenAbvGr 1460 non-null int64
53 KitchenQual 1460 non-null object
54 TotRmsAbvGrd 1460 non-null int64
55 Functional 1460 non-null object
56 Fireplaces 1460 non-null int64
57 FireplaceQu 770 non-null object
58 GarageType 1379 non-null object
59 GarageYrBlt 1379 non-null float64
60 GarageFinish 1379 non-null object
61 GarageCars 1460 non-null int64
62 GarageArea 1460 non-null int64
63 GarageQual 1379 non-null object
64 GarageCond 1379 non-null object
65 PavedDrive 1460 non-null object
66 WoodDeckSF 1460 non-null int64
67 OpenPorchSF 1460 non-null int64
68 EnclosedPorch 1460 non-null int64
69 3SsnPorch 1460 non-null int64
70 ScreenPorch 1460 non-null int64
71 PoolArea 1460 non-null int64
72 PoolQC 7 non-null object
73 Fence 281 non-null object
74 MiscFeature 54 non-null object
75 MiscVal 1460 non-null int64
76 MoSold 1460 non-null int64
77 YrSold 1460 non-null int64
78 SaleType 1460 non-null object
79 SaleCondition 1460 non-null object
80 SalePrice 1460 non-null int64
dtypes: float64(3), int64(35), object(43)
memory usage: 924.0+ KB
対数変換
訓練データの'SalePrice'には、住宅の販売価格が格納されています。'SalePrice'の分布状況を確認してみます。
sns.displot(train['SalePrice'])
出力結果

分布状況が低価格帯に偏っていて、やや右側に尾を引くような分布になっています。
回帰分析をする上では正規分布にならなければ精度が下がるので、対数変換を利用して正規分布に変換します。

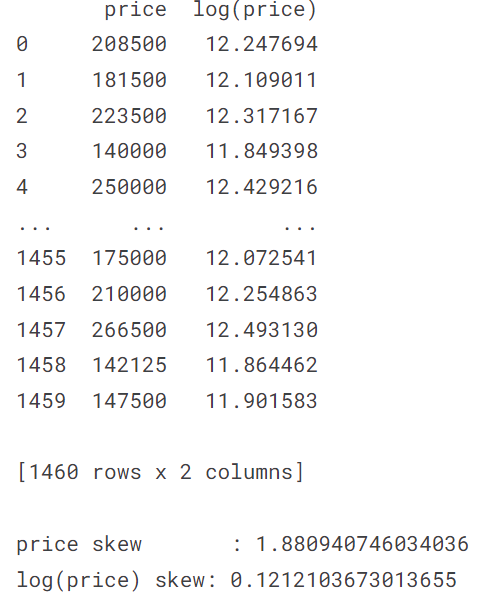
ヒストグラムを見ると、対数変換したことで正規分布に近づいているのが分かります。また、歪度(分布が正規分布からどれだけ歪んでいるかを表す統計量)をみても、対数変換後の方が0に近い値であるため、分布が正規分布に近づいたということがいえます。今回のように対数変換することで正規分布に近づく変数は多くあります。今回は、RMSEで評価するために対数変換したら、たまたま正規分布に近づきました。ただし、目的変数を正規分布にする必要は必ずしもあるわけではありません。回帰分析において、残差が正規分布であることが望ましいのですが、目的変数を正規分布に近づけると残差も正規分布に近づく場合が多くあります。
訓練データとテストデータを連結
欠損値処理
ここからは、欠損値の処理をしていきます。欠損値の処理には、主に以下の2つがあります。
①欠損値を含む行または列の削除
②欠損値を代表値などで埋める
最も欠損が多かったのはPoolQC(プールの質)で、更に文字列のデータした。このカラムは削除したくなりますが、Kaggleの提供しているデータdata_description.txtにPoolQCを確認すると次のように記載されています。
PoolQC: Pool quality
Ex Excellent
Gd Good
TA Average/Typical
Fa Fair
NA No Pool
つまり、NaN(欠損)は「No Pool」の事であり、データの欠損そのものが情報となっています。他の変数を確認してもobject型の変数のほとんどが該当の施設が存在しないという意味でデータが欠損していました。そこで、今回は、object型の欠損値はNAで埋めることにします。(より詳細にデータを確認すると、他のカラムを参照すると、施設が存在しているけれど、データが欠損している箇所もあるので、もう少し丁寧に前処理を行うべきだと思います。)
ここで、もう一度データの欠損状況を確認します。
出力結果
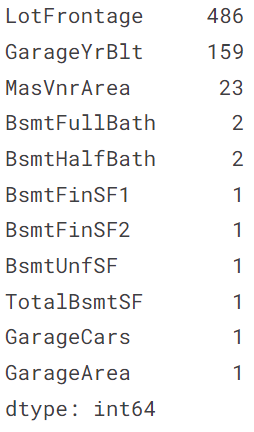
最も欠損の多いLotFrontageから見ていきます。LotFrontageの説明をみると、 Linear feet of street connected to property(物件に隣接した道路の長さ)とかいてあります。区画サイズによってLotFrontageの値がほぼ決まると考えられます。他の方の方法を参考にさせていただいたのですが、区画サイズは地区ごとに標準のサイズが決まっているので、地区ごとにLotFrontageの値がほぼ決まるのではないかと考えられます。そこで、地区を表すNeighborhoodごとのLotFrontageを箱ひげ図で見てみます。
sns.boxplot(data=all_data, x='Neighborhood', y='LotFrontage')
出力結果
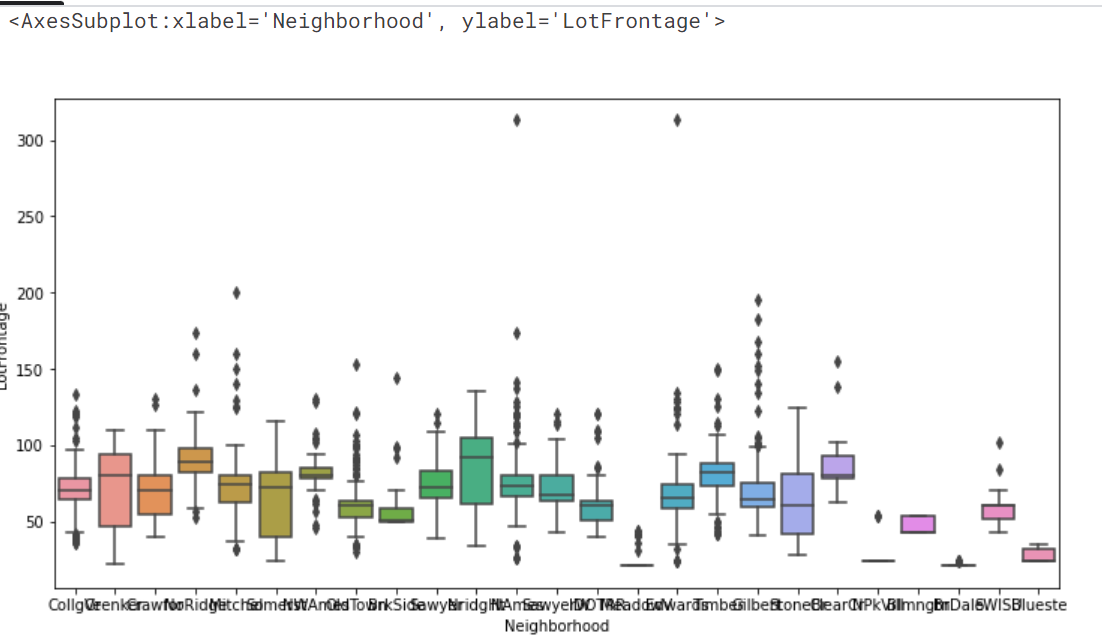
確かに見た感じ、地区ごとにLotFrontageの値がほぼ決まってそうです。そこで、LotFrontageの欠損値をNeighborhoodごとの代表値で埋めることにします。代表値といえば、平均値が思い浮かびますが、今回は外れ値の影響が大きそうなので、中央値で埋めることにしました。そのためのコードが合っているのか自信がないのですが、もし間違っていたらご指摘いただきたいです。
次に欠損値の多かったGarageYrBltをみていきます。データを具体的に見てみます。
all_data['GarageYrBlt']
出力結果

GarageYrBltは見ての通り、ガレージが建設された年を表すデータです。そのため、欠損値は、ガレージがないことを意味しているのではないかと推測できます。しかし、ガレージが無いことを表すデータはGarageYrBltの他にGarageQual、GarageCondから読み取れます。また、GarageYrBltはYearBuilt(住宅の建設された年)とも相関が高そうであり、欠損値を埋めることが難しいので、この列は削除することにします。
all_data = all_data.drop('GarageYrBlt', axis=1)
残りの欠損値のある列について考えましょう。ほとんどの列が、該当の施設が存在しないという意味でデータが欠損していました。そのため、欠損値は、0で埋めていきます。
all_data = all_data.fillna(0)
数字の大小関係が予測に影響しない列の処理
数字が入っているが、数字の大小関係が予測に影響を与えない方が良いものは文字列にすべきです。
例えば、MSSubClass(住居の種類)は
{'1-STORY 1946 & NEWER ALL STYLES' : 20 ,'1-STORY 1945 & OLDER' : 30 , '1-STORY W/FINISHED ATTIC ALL AGES' : 40,・・・, '2 FAMILY CONVERSION - ALL STYLES AND AGES' : 190 }と割り当てられている場合、数の大小に意味はないので{'1-STORY 1946 & NEWER ALL STYLES' : '20' ,'1-STORY 1945 & OLDER' : '30' , '1-STORY W/FINISHED ATTIC ALL AGES' : '40' ,・・・, '2 FAMILY CONVERSION - ALL STYLES AND AGES' : '190' }に変換します。
num_str_list = ['MSSubClass','YrSold','MoSold']
for i in num_str_list:
all_data[i] = all_data[i].astype(str)
相関の確認
#相関係数が0.7以上の変数の組を表示 all_data_corr = all_data.corr() all_data_corr[all_data_corr > 0.7].stack()
出力結果
LotFrontage LotFrontage 1.000000
LotArea LotArea 1.000000
OverallQual OverallQual 1.000000
OverallCond OverallCond 1.000000
YearBuilt YearBuilt 1.000000
YearRemodAdd YearRemodAdd 1.000000
MasVnrArea MasVnrArea 1.000000
BsmtFinSF1 BsmtFinSF1 1.000000
BsmtFinSF2 BsmtFinSF2 1.000000
BsmtUnfSF BsmtUnfSF 1.000000
TotalBsmtSF TotalBsmtSF 1.000000
1stFlrSF 0.801376
1stFlrSF TotalBsmtSF 0.801376
1stFlrSF 1.000000
2ndFlrSF 2ndFlrSF 1.000000
LowQualFinSF LowQualFinSF 1.000000
GrLivArea GrLivArea 1.000000
TotRmsAbvGrd 0.808354
BsmtFullBath BsmtFullBath 1.000000
BsmtHalfBath BsmtHalfBath 1.000000
FullBath FullBath 1.000000
HalfBath HalfBath 1.000000
BedroomAbvGr BedroomAbvGr 1.000000
KitchenAbvGr KitchenAbvGr 1.000000
TotRmsAbvGrd GrLivArea 0.808354
TotRmsAbvGrd 1.000000
Fireplaces Fireplaces 1.000000
GarageCars GarageCars 1.000000
GarageArea 0.889890
GarageArea GarageCars 0.889890
GarageArea 1.000000
WoodDeckSF WoodDeckSF 1.000000
OpenPorchSF OpenPorchSF 1.000000
EnclosedPorch EnclosedPorch 1.000000
3SsnPorch 3SsnPorch 1.000000
ScreenPorch ScreenPorch 1.000000
PoolArea PoolArea 1.000000
MiscVal MiscVal 1.000000
dtype: float64
相関係数を確認してみたところ、
・TotalBsmtSF 1stFlrSF
・GrLivArea TotRmsAbvGrd
・GarageArea GarageCars
以上の列の組に強い相関がありました。GarageCars(車容量)とGarageArea(車庫の大きさ)などは項目の意味からも相関の強さは明らかです。これらの変数は多重共線性の点から一つに絞る必要があります。多重共線性とは学習モデルに用いる説明変数同士で相関係数が高い場合、数値的に不安定な予測を引き起こしてしまうことを指します。そのため、相関関係が高いと考えられる説明変数を外したり、それらの変数を合成して新しい変数をつくる等の処理が必要です。
特徴量エンジニアリング
特徴量エンジニアリングでは予測の精度向上に貢献しそうな新しい変数を追加していきます。
このように、設備があるかないかを0,1で分類したり、面積等を合計したりして、新たな特徴量を作ります。工夫次第で様々な特徴量を作成できそうです。
特徴量選択
先ほどは、新たに特徴量を作成しましたが、特徴量は多ければ良いというものではありません。ノイズにより予測精度が落ちてしまうことがあるのです。
そこで、相関が高いカラムを片方削除したり、重要度が低いカラムを削除したりする等してノイズによる影響を減らします。
カテゴリ変数のエンコーディング
Label Encoding
One-Hot-Encoding


# One Hotエンコーディングで生成した列を1つ削除する all_data = pd.get_dummies(all_data,drop_first=True)
回帰モデルによる学習
標準化
from sklearn.preprocessing import StandardScaler #訓練データとテストデータを標準化 sc = StandardScaler() all_data = sc.fit_transform(all_data)
データの切り分け
# 訓練データとテストデータに分ける X_train = all_data[:train.shape[0]] X_test = all_data[train.shape[0]:] y = train.SalePrice
線形回帰
リッジ回帰
# リッジ回帰モデルを生成
model_ridge = Ridge()
# L2正則化の強度を10パターン用意
alphas = [0.05, 0.1, 1, 10, 50, 100, 200, 300, 400, 500]
# 正則化の各強度でリッジ回帰を実行
# 5分割のクロスバリデーションでRMSEを求め、その平均を取得
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean()
for alpha in alphas]
# cv_ridgeをSeriesオブジェクトに変換
cv_ridge = pd.Series(cv_ridge, index = alphas)
# スコアを出力
print('Ridge RMSE loss:')
print(cv_ridge, '\n')
# スコアの平均を出力
print('Ridge RMSE loss Mean:')
print(cv_ridge.mean())
# 正則化の強度別のスコアをグラフにする
plt.figure(figsize=(10, 5)) # 描画エリアのサイズ
plt.plot(cv_ridge) # cv_ridgeをプロット
plt.grid() # グリッド表示
plt.title('Validation - by regularization strength')
plt.xlabel('Alpha')
plt.ylabel('RMSE')
plt.show()


ラッソ回帰

GBDT(勾配ブースティング木)
GBDTの実装
Learning API

# 30回以降の検証データと訓練データのRMSEをグラフにする
plt.figure(figsize=(8, 6)) # 描画エリアのサイズ
plt.plot(cross_val.loc[30:,["test-rmse-mean", "train-rmse-mean"]])
plt.grid() # グリッド表示
plt.xlabel('num_boost_round')
plt.ylabel('RMSE')
plt.show()

scikit-Learn API
# xgboostで学習する
model_xgb = xgb.XGBRegressor(
n_estimators=242, # 決定木の本数
max_depth=5, # 決定木の深さ
learning_rate=0.1) # 学習率0.1
model_xgb.fit(X_train, y)
print('xgboost RMSE loss:')
print(rmse_cv(model_xgb).mean())

アンサンブル
lasso_preds = np.exp(model_lasso.predict(X_test)) xgb_preds = np.exp(model_xgb.predict(X_test))
preds = lasso_preds*0.7 + xgb_preds*0.3
提出用csvを作成
solution = pd.DataFrame({"id":test.Id, "SalePrice":preds})
solution.to_csv("ridge_sol.csv", index = False)
スコアは0.12882で順位は4400人中955位でした。
0 件のコメント:
コメントを投稿