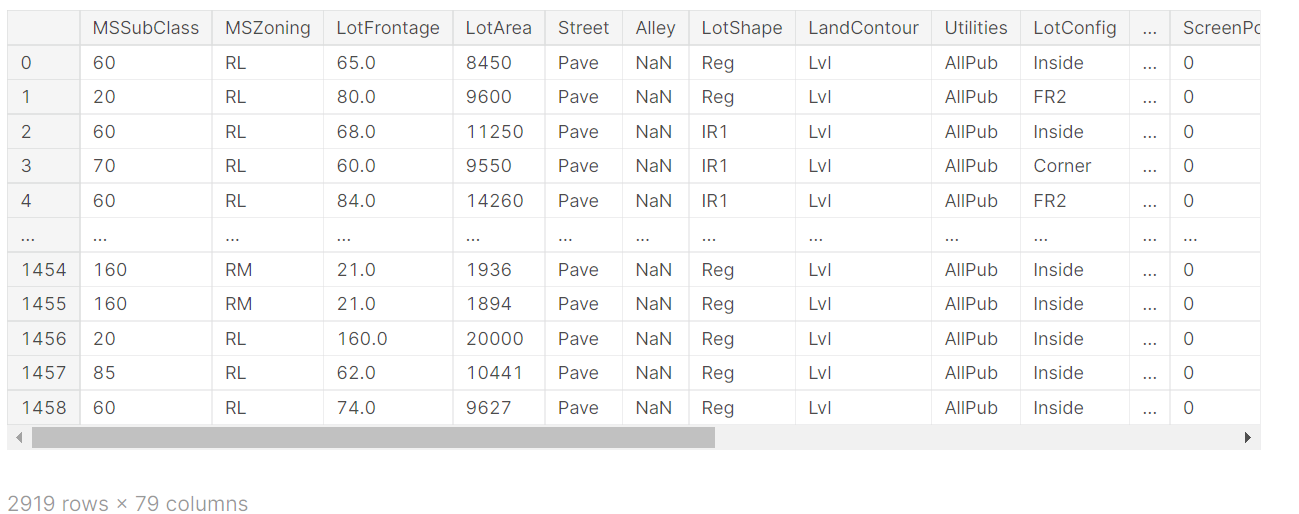
訓練データには1460レコード、テストデータには1459レコードのデータが収録されています。訓練データのカラム数は81ですが、テストデータでは予測に使用する'SalePrice'がないので、カラム数は80となっています。訓練データの情報をDataFrame.info()メソッドで出力してみます。
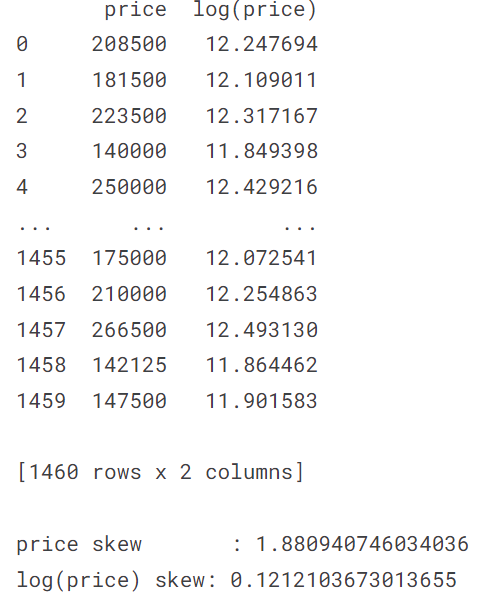
# SalePriceの値を、底をeとする対数に変換する
train["SalePrice"] = np.log(train["SalePrice"])
ヒストグラムを見ると、対数変換したことで正規分布に近づいているのが分かります。また、歪度(分布が正規分布からどれだけ歪んでいるかを表す統計量)をみても、対数変換後の方が0に近い値であるため、分布が正規分布に近づいたということがいえます。今回のように対数変換することで正規分布に近づく変数は多くあります。今回は、RMSEで評価するために対数変換したら、たまたま正規分布に近づきました。ただし、目的変数を正規分布にする必要は必ずしもあるわけではありません。回帰分析において、残差が正規分布であることが望ましいのですが、目的変数を正規分布に近づけると残差も正規分布に近づく場合が多くあります。
訓練データとテストデータを連結
ここで、データの前処理をまとめて、行えるように、訓練データとテストデータを連結して1つのデータフレームにします。前処理では、'Id'と'SalePrice'のカラムは必要ないので、'MSSubClass'~'SaleCondition'のカラムのみを抽出してから連結します。
# 訓練データとテストデータからMSSubClass~SaleConditionのカラムのみを抽出して連結
all_data = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'],
test.loc[:,'MSSubClass':'SaleCondition']))
# 連結したデータを出力
all_data
欠損値処理
ここからは、欠損値の処理をしていきます。欠損値の処理には、主に以下の2つがあります。
①欠損値を含む行または列の削除
②欠損値を代表値などで埋める
最も欠損が多かったのはPoolQC(プールの質)で、更に文字列のデータした。このカラムは削除したくなりますが、Kaggleの提供しているデータdata_description.txtにPoolQCを確認すると次のように記載されています。
PoolQC: Pool quality
Ex Excellent
Gd Good
TA Average/Typical
Fa Fair
NA No Pool
つまり、NaN(欠損)は「No Pool」の事であり、データの欠損そのものが情報となっています。他の変数を確認してもobject型の変数のほとんどが該当の施設が存在しないという意味でデータが欠損していました。そこで、今回は、object型の欠損値はNAで埋めることにします。(より詳細にデータを確認すると、他のカラムを参照すると、施設が存在しているけれど、データが欠損している箇所もあるので、もう少し丁寧に前処理を行うべきだと思います。)
#na_col_listに欠損値を含む説明変数のリストを作成
na_col_list = all_data.isnull().sum()[all_data.isnull().sum()>0].index.tolist()
#連結したデータのobject抽出
na_obj = all_data[na_col_list].dtypes[all_data[na_col_list].dtypes=='object'].index.tolist()
#データの欠損値をNAで補間
for i in na_obj:
all_data.loc[all_data[i].isnull(),i] = 'NA'
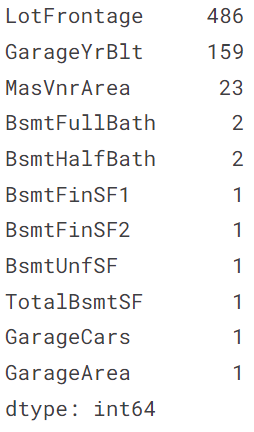
ここで、もう一度データの欠損状況を確認します。
# データの欠損状況
all_data.isnull().sum()[all_data.isnull().sum()>0].sort_values(ascending=False)
出力結果
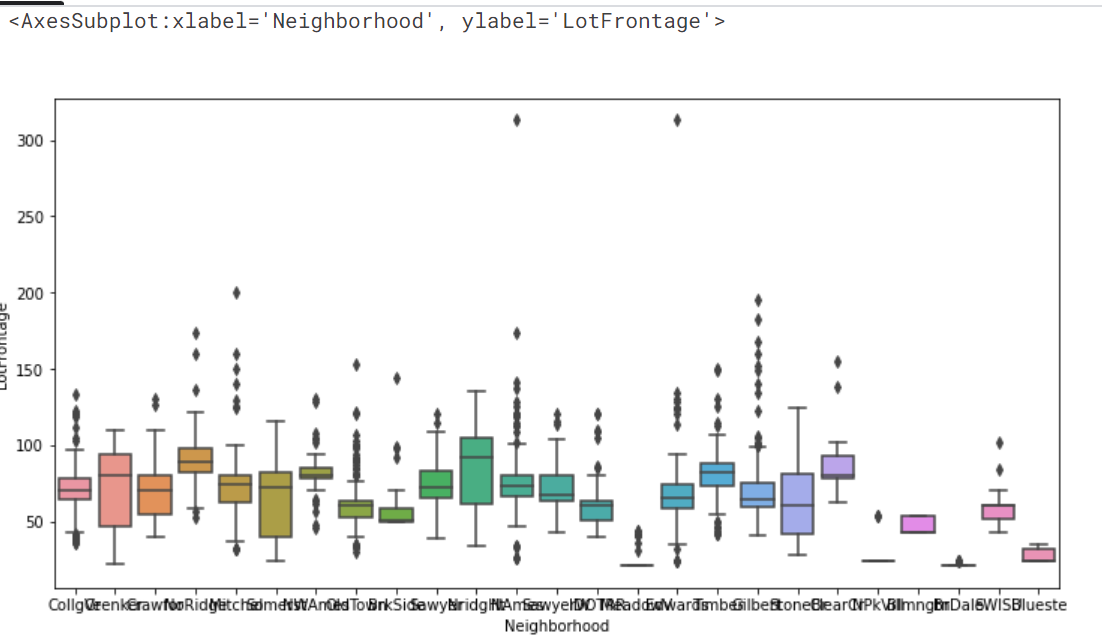
最も欠損の多いLotFrontageから見ていきます。LotFrontageの説明をみると、 Linear feet of street connected to property(物件に隣接した道路の長さ)とかいてあります。区画サイズによってLotFrontageの値がほぼ決まると考えられます。他の方の方法を参考にさせていただいたのですが、区画サイズは地区ごとに標準のサイズが決まっているので、地区ごとにLotFrontageの値がほぼ決まるのではないかと考えられます。そこで、地区を表すNeighborhoodごとのLotFrontageを箱ひげ図で見てみます。
sns.boxplot(data=all_data, x='Neighborhood', y='LotFrontage')
出力結果
確かに見た感じ、地区ごとにLotFrontageの値がほぼ決まってそうです。そこで、LotFrontageの欠損値をNeighborhoodごとの代表値で埋めることにします。代表値といえば、平均値が思い浮かびますが、今回は外れ値の影響が大きそうなので、中央値で埋めることにしました。そのためのコードが合っているのか自信がないのですが、もし間違っていたらご指摘いただきたいです。
all_data.LotFrontage[all_data.LotFrontage.isnull()] = all_data.groupby("Neighborhood").LotFrontage.median()[all_data.loc[all_data.LotFrontage.isnull(),"Neighborhood"]]
次に欠損値の多かったGarageYrBltをみていきます。データを具体的に見てみます。
all_data['GarageYrBlt']
出力結果
GarageYrBltは見ての通り、ガレージが建設された年を表すデータです。そのため、欠損値は、ガレージがないことを意味しているのではないかと推測できます。しかし、ガレージが無いことを表すデータはGarageYrBltの他にGarageQual、GarageCondから読み取れます。また、GarageYrBltはYearBuilt(住宅の建設された年)とも相関が高そうであり、欠損値を埋めることが難しいので、この列は削除することにします。
all_data = all_data.drop('GarageYrBlt', axis=1)
残りの欠損値のある列について考えましょう。ほとんどの列が、該当の施設が存在しないという意味でデータが欠損していました。そのため、欠損値は、0で埋めていきます。
all_data = all_data.fillna(0)
数字の大小関係が予測に影響しない列の処理
数字が入っているが、数字の大小関係が予測に影響を与えない方が良いものは文字列にすべきです。
例えば、MSSubClass(住居の種類)は
{'1-STORY 1946 & NEWER ALL STYLES' : 20 ,'1-STORY 1945 & OLDER' : 30 , '1-STORY W/FINISHED ATTIC ALL AGES' : 40,・・・, '2 FAMILY CONVERSION - ALL STYLES AND AGES' : 190 }と割り当てられている場合、数の大小に意味はないので{'1-STORY 1946 & NEWER ALL STYLES' : '20' ,'1-STORY 1945 & OLDER' : '30' , '1-STORY W/FINISHED ATTIC ALL AGES' : '40' ,・・・, '2 FAMILY CONVERSION - ALL STYLES AND AGES' : '190' }に変換します。
num_str_list = ['MSSubClass','YrSold','MoSold']
for i in num_str_list:
all_data[i] = all_data[i].astype(str)
相関の確認
#相関係数が0.7以上の変数の組を表示
all_data_corr = all_data.corr()
all_data_corr[all_data_corr > 0.7].stack()
出力結果
LotFrontage LotFrontage 1.000000
LotArea LotArea 1.000000
OverallQual OverallQual 1.000000
OverallCond OverallCond 1.000000
YearBuilt YearBuilt 1.000000
YearRemodAdd YearRemodAdd 1.000000
MasVnrArea MasVnrArea 1.000000
BsmtFinSF1 BsmtFinSF1 1.000000
BsmtFinSF2 BsmtFinSF2 1.000000
BsmtUnfSF BsmtUnfSF 1.000000
TotalBsmtSF TotalBsmtSF 1.000000
1stFlrSF 0.801376
1stFlrSF TotalBsmtSF 0.801376
1stFlrSF 1.000000
2ndFlrSF 2ndFlrSF 1.000000
LowQualFinSF LowQualFinSF 1.000000
GrLivArea GrLivArea 1.000000
TotRmsAbvGrd 0.808354
BsmtFullBath BsmtFullBath 1.000000
BsmtHalfBath BsmtHalfBath 1.000000
FullBath FullBath 1.000000
HalfBath HalfBath 1.000000
BedroomAbvGr BedroomAbvGr 1.000000
KitchenAbvGr KitchenAbvGr 1.000000
TotRmsAbvGrd GrLivArea 0.808354
TotRmsAbvGrd 1.000000
Fireplaces Fireplaces 1.000000
GarageCars GarageCars 1.000000
GarageArea 0.889890
GarageArea GarageCars 0.889890
GarageArea 1.000000
WoodDeckSF WoodDeckSF 1.000000
OpenPorchSF OpenPorchSF 1.000000
EnclosedPorch EnclosedPorch 1.000000
3SsnPorch 3SsnPorch 1.000000
ScreenPorch ScreenPorch 1.000000
PoolArea PoolArea 1.000000
MiscVal MiscVal 1.000000
dtype: float64
相関係数を確認してみたところ、
・TotalBsmtSF 1stFlrSF
・GrLivArea TotRmsAbvGrd
・GarageArea GarageCars
以上の列の組に強い相関がありました。GarageCars(車容量)とGarageArea(車庫の大きさ)などは項目の意味からも相関の強さは明らかです。これらの変数は多重共線性の点から一つに絞る必要があります。多重共線性とは学習モデルに用いる説明変数同士で相関係数が高い場合、数値的に不安定な予測を引き起こしてしまうことを指します。そのため、相関関係が高いと考えられる説明変数を外したり、それらの変数を合成して新しい変数をつくる等の処理が必要です。
特徴量エンジニアリング
特徴量エンジニアリングでは予測の精度向上に貢献しそうな新しい変数を追加していきます。
# 特徴量エンジニアリングによりカラムを追加する関数
def add_new_columns(df):
# 建物内の総面積 = 1階の面積 + 2階の面積 + 地下の面積
df['TotalSF'] = df['1stFlrSF'] + df['2ndFlrSF'] + df['TotalBsmtSF']
# 一部屋あたりの平均面積 = 建物の総面積 / 部屋数
df['AreaPerRoom'] = df['TotalSF']/df['TotRmsAbvGrd']
# 築年数 + 最新リフォーム年 : この値が大きいほど値段が高くなりそう
df['YearBuiltPlusRemod']=df['YearBuilt']+df['YearRemodAdd']
# お風呂の総面積
# Full bath : 浴槽、シャワー、洗面台、便器全てが備わったバスルーム
# Half bath : 洗面台、便器が備わった部屋)(シャワールームがある場合もある)
# シャワーがない場合を想定してHalf Bathには0.5の係数をつける
df['TotalBathrooms'] = (df['FullBath'] + (0.5 * df['HalfBath']) + df['BsmtFullBath'] + (0.5 * df['BsmtHalfBath']))
# 合計の屋根付きの玄関の総面積
# Porch : 屋根付きの玄関 日本風にいうと縁側
df['TotalPorchSF'] = (df['OpenPorchSF'] + df['3SsnPorch'] + df['EnclosedPorch'] + df['ScreenPorch'] + df['WoodDeckSF'])
# 2階の有無
df['Has2ndFloor'] = df['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
# カラムを追加
add_new_columns(all_data)
このように、設備があるかないかを0,1で分類したり、面積等を合計したりして、新たな特徴量を作ります。工夫次第で様々な特徴量を作成できそうです。
特徴量選択
先ほどは、新たに特徴量を作成しましたが、特徴量は多ければ良いというものではありません。ノイズにより予測精度が落ちてしまうことがあるのです。
そこで、相関が高いカラムを片方削除したり、重要度が低いカラムを削除したりする等してノイズによる影響を減らします。
dr_cols = ['GarageCars','1stFlrSF','2ndFlrSF','TotalBsmtSF','TotalSF','TotRmsAbvGrd','YearBuilt','YearRemodAdd','FullBath','HalfBath','BsmtFullBath','BsmtHalfBath','OpenPorchSF','3SsnPorch','EnclosedPorch','ScreenPorch','WoodDeckSF' ]
for i in dr_cols:
all_data = all_data.drop(i, axis=1)
カテゴリ変数のエンコーディング
カテゴリ変数とは、身長や年齢のように数値で表せる変数ではなく、グループ・属性(色・国など)を分類する用途で示される変数を指します。また、カテゴリ変数は「名義変数」と「順序変数」で分けることができます。名義変数は、並び替えや順序付けができないカテゴリ変数です。それに対して、順序変数は、並び替えや順序付けが可能なカテゴリ変数です。カテゴリ変数はそのまま学習に使うことができないので、数値に変換することが求められます。その処理過程をエンコーディングといいます。
Label Encoding
まず、順序変数に対してはLabel Encodingを行います。
Label Encodingとは、カテゴリ変数の項目数に応じて連番を渡すデータ変換方法です。後に紹介するOne-Hot-Encodingと異なり、新しく生成される変数は1つのみでいいという特徴があります。scikit-learnのLabelEncoderを用いると、それぞれのカテゴリに自動で数値を割り当てることができます。なお、この時の数値はABC順で自動的に決められます。モデルによってはカテゴリの順番も重要な要素になってくるので、そのような場合は自分で順番を指定する必要があるため、可能ならば、1つずつ順序変数を詳細に見ていくべきだと思います。
また、カテゴリ変数を数値変数に変換しても、その数値変数には「数値的な意味」がありません。例えば、「a~e」のカテゴリ変数を、「0~4」の数値変数に変換したとしても
「e:4」が「b:1」の4倍大きいわけではありません。
そのため、機械学習において「決定木」をベースにした手法以外では、正確ではないモデルが出来上がる可能性があります。一方で「決定木」や「ランダムフォレスト」といった手法では、数値変数も分岐を繰り返して予測値に反映できるため、学習に用いることが可能です。コンペなどでよく利用されているGBDTにおいても、Label Encodingはよく利用されています。
例えば、PoolQCは以下のように変換します。
PoolQC: Pool quality
Ex Excellent →4
Gd Good →3
TA Average/Typical →2
Fa Fair →1
NA No Pool →0
#ラベルエンコーディングするクラス
from sklearn.preprocessing import LabelEncoder
#インスタンス
LE = LabelEncoder()
LE_cols = ['Utilities','ExterQual','ExterCond','BsmtQual','BsmtCond','BsmtExposure','BsmtFinType1','BsmtFinType2','HeatingQC','KitchenQual','FireplaceQu','GarageFinish','GarageQual','GarageCond','PavedDrive','PoolQC','Fence']
for i in LE_cols:
#Label エンコーディング
LE.fit_transform(all_data[i].values)
#データ変換
all_data[i] = LE.fit_transform(all_data[i].values)
One-Hot-Encoding
名義変数に対しては、One-Hot-Encodingを行います。One-Hot-Encodingでは、カテゴリ変数に含まれる項目を新たな列として扱い、各列の値に0または1を与えていく方法です。カテゴリに用意された対象項目に該当する場合「1」該当しない場合「0」を渡します。
大量のカテゴリが含まれているカテゴリ変数の場合は、ダミー変数の数が膨大になってしまうのでこの方法を用いるのは難しい場合もあります。また、他にも多重共線性に注意する必要があります。
多重共線性を回避するためには「One-Hot-Encodingで生成した列を1つ削除する」だけで良いです。get_dummyies()メソッドを使用する場合、drop_first=Trueとして引数を渡すと、最初の列を削除できます。(ちなみに、この手法はdummy encodingと呼ばれています。多重共線性を回避するための方法としては、他にもeffecct encodingという手法もあります。)
例えば、SaleConditionには、Normal、Abnorml、AdjLand等の6つの対象項目がありますが、drop_first=Trueとしてget_dummyies()メソッドを使用すると、SaleCondition_Abnormlの列が削除されて以下のように変換されます。つまり、他の5つの対象項目全てが0と観測された場合、SaleConditionはAbnormlと判断できるため、ダミー変数を1つ削除したところでSaleConditionの情報が消失することはありません。
変換前 変換後
# One Hotエンコーディングで生成した列を1つ削除する
all_data = pd.get_dummies(all_data,drop_first=True)
今回は上記2つのEncodingを使いましたが、Count Encoding、Target Encodingといった手法もあり、より工夫できそうなところです。ここで、もう一度相関係数を確認して、相関関係が高いと考えられる説明変数を外します。
#相関係数が0.7以上の変数の組を表示
all_data_corr = all_data.corr()
all_data_corr[(all_data_corr > 0.7) & (all_data_corr != 1)].stack()
出力結果
KitchenAbvGr MSSubClass_90 0.751203
BldgType_Duplex 0.751203
Has2ndFloor HouseStyle_2Story 0.753648
MSSubClass_190 BldgType_2fmCon 0.975118
MSSubClass_20 HouseStyle_1Story 0.756927
MSSubClass_45 HouseStyle_1.5Unf 0.864323
MSSubClass_60 HouseStyle_2Story 0.753204
MSSubClass_80 HouseStyle_SLvl 0.958428
MSSubClass_85 HouseStyle_SFoyer 0.755819
MSSubClass_90 KitchenAbvGr 0.751203
MSZoning_FV Neighborhood_Somerst 0.867135
Neighborhood_NPkVill Exterior2nd_Brk Cmn 0.798647
Neighborhood_Somerst MSZoning_FV 0.867135
BldgType_2fmCon MSSubClass_190 0.975118
BldgType_Duplex KitchenAbvGr 0.751203
HouseStyle_1.5Unf MSSubClass_45 0.864323
HouseStyle_1Story MSSubClass_20 0.756927
HouseStyle_2Story Has2ndFloor 0.753648
MSSubClass_60 0.753204
HouseStyle_SFoyer MSSubClass_85 0.755819
HouseStyle_SLvl MSSubClass_80 0.958428
Exterior1st_AsphShn Exterior2nd_AsphShn 0.706864
Exterior1st_CemntBd Exterior2nd_CmentBd 0.983411
Exterior1st_HdBoard Exterior2nd_HdBoard 0.887999
Exterior1st_MetalSd Exterior2nd_MetalSd 0.969712
Exterior1st_Plywood Exterior2nd_Plywood 0.740022
Exterior1st_Stucco Exterior2nd_Stucco 0.729910
Exterior1st_VinylSd Exterior2nd_VinylSd 0.978178
Exterior1st_Wd Sdng Exterior2nd_Wd Sdng 0.861610
Exterior2nd_AsphShn Exterior1st_AsphShn 0.706864
Exterior2nd_Brk Cmn Neighborhood_NPkVill 0.798647
Exterior2nd_CmentBd Exterior1st_CemntBd 0.983411
Exterior2nd_HdBoard Exterior1st_HdBoard 0.887999
Exterior2nd_MetalSd Exterior1st_MetalSd 0.969712
Exterior2nd_Plywood Exterior1st_Plywood 0.740022
Exterior2nd_Stucco Exterior1st_Stucco 0.729910
Exterior2nd_VinylSd Exterior1st_VinylSd 0.978178
Exterior2nd_Wd Sdng Exterior1st_Wd Sdng 0.861610
SaleType_New SaleCondition_Partial 0.986573
SaleCondition_Partial SaleType_New 0.986573
dtype: float64
出力結果をみると、MSSubClassとHouseStyle、Exterior1stとExterior2ndはもともと関係性が強そうなので、エンコーディングする前にどちらかのカラムを削除した方が良かったかもしれません。
dr_cols = ['KitchenAbvGr','BldgType_Duplex','BldgType_2fmCon','HouseStyle_1Story','HouseStyle_SLvl','HouseStyle_SFoyer','MSZoning_FV','Exterior2nd_Brk Cmn','Exterior2nd_AsphShn','Exterior2nd_CmentBd','Exterior2nd_HdBoard','Exterior2nd_MetalSd','Exterior2nd_Plywood','Exterior2nd_Stucco','Exterior2nd_VinylSd','Exterior2nd_Wd Sdng','SaleCondition_Partial' ]
for i in dr_cols:
all_data = all_data.drop(i, axis=1)
回帰モデルによる学習
標準化
例えば、面積と年数では同じ単位で比較できないので、どちらかの変数を重視してしまうモデルができてしまう可能性があります。そこで、特徴量がもつ値の重みを平等にするために、データを標準化します。標準化は、平均0、分散1にスケーリングして扱いやすいものに整えることであり、データの分布が正規分布に従っている場合に特に効果的な手法です。そのため、SalePriceと同じように、歪度が大きい説明変数の分布を対数変換して正規分布に近づけてから標準化してもいいのですが、標準化は必ずしもデータの分布が正規分布でなくても使えるので、本記事ではそのまま標準化することにします。
from sklearn.preprocessing import StandardScaler
#訓練データとテストデータを標準化
sc = StandardScaler()
all_data = sc.fit_transform(all_data)
データの切り分け
結合した訓練データとテストデータをそれぞれ切り分け、対数変換したSalePriceを、訓練時の正解データとして用意します。
# 訓練データとテストデータに分ける
X_train = all_data[:train.shape[0]]
X_test = all_data[train.shape[0]:]
y = train.SalePrice
線形回帰
線形回帰では、回帰式を用いた、予測が行われます。線形回帰の目的は、回帰式と実測値(正解値)が最小になるwを求めることになります。このときの誤差E(w)の最も単純な方法はMSE(平均二乗誤差)です。
今回の予測では、MSEの平方根をとったRMSE(二乗平方根誤差)を誤差関数(損失関数)として用いています。RMSEは、予測値が上振れ(正解値を大きく上回る)した場合に、より大きな損失E(w)になるので、価格の予想に適しているといえます。
rmse_cv()関数をRMSEを計算する関数として定義します。検証は、クロスバリュエーションでデータを5個に分割して行うことにします。
def rmse_cv(model):
"""二乗平均平方根誤差
Parameters:
model(obj): Modelオブジェクト
Returns:
(float)訓練データの出力値と正解値とのRMSE
"""
# クロスバリデーションによる二乗平均平方根誤差の取得
rmse = np.sqrt(
-cross_val_score(
model, X_train, y,
scoring="neg_mean_squared_error", # 平均二乗誤差を指定
cv = 5)) # データを5分割
return(rmse)
機械学習は、一般的に学習データに対する損失関数を最小化するように学習しますが、
これだけでは細かくフィッティングした複雑なモデルが生成され、過学習が起こります。
そこで、損失関数にモデルの複雑さを表す指標(正則化項)を加え、これを最小化するよう学習すれば、
性能と複雑さ、すなわち過学習と未学習のバランスを取った学習が実現できます。
MSEを最小にするようなパラメータを求める方法が最小二乗法ですが、複雑さを制御する(過剰適合しないようにする)パラメータがあれがいいのですが、それはありません。パラメータを導入する方法としてリッジ回帰とラッソ回帰があります。
リッジ回帰
リッジ回帰は正則化された線形回帰の1つで、線形関数の誤差関数に重みの二乗和(L2正則化項)を加えたものです。L2正則化項は、数学的にものの長さを表すユークリッド距離とも呼ばれています。パラメータの値が増大するのを防ぐことでオーバーフィッティングを防ぐ。
リッジ回帰は、sckit-learnのsklearn.linear_model.Ridgeクラスで実装し、L2正則化の強度(係数)を10パターン用意して、それぞれの強度で精度を測定します。
正則化の強弱、つまり、モデルの複雑さは、alphaの値を変化させることにより決められます。
alphaを増やす -> 正則化が強くなる -> モデルは簡潔になる
alphaを減らす -> 正則化が弱くなる -> モデルは複雑になる
alphaの値が何が良いかはデータ次第です。ちなみに、alphaを0とすると、通常の最小二乗法による回帰になります。
# リッジ回帰モデルを生成
model_ridge = Ridge()
# L2正則化の強度を10パターン用意
alphas = [0.05, 0.1, 1, 10, 50, 100, 200, 300, 400, 500]
# 正則化の各強度でリッジ回帰を実行
# 5分割のクロスバリデーションでRMSEを求め、その平均を取得
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean()
for alpha in alphas]
# cv_ridgeをSeriesオブジェクトに変換
cv_ridge = pd.Series(cv_ridge, index = alphas)
# スコアを出力
print('Ridge RMSE loss:')
print(cv_ridge, '\n')
# スコアの平均を出力
print('Ridge RMSE loss Mean:')
print(cv_ridge.mean())
# 正則化の強度別のスコアをグラフにする
plt.figure(figsize=(10, 5)) # 描画エリアのサイズ
plt.plot(cv_ridge) # cv_ridgeをプロット
plt.grid() # グリッド表示
plt.title('Validation - by regularization strength')
plt.xlabel('Alpha')
plt.ylabel('RMSE')
plt.show()
ラッソ回帰
ラッソ回帰は正則化された線形回帰の1つで、線形関数の誤差関数に重みの和(L1正則化項)を加えたものです。L1正則化項は、各要素の絶対値の和をとったもので、マンハッタン距離とも言われます。「碁盤の目状の町である2点間を移動するのに歩く距離」みたいなイメージです。ラッソ回帰では自動的に重要な特徴量を選択する役割を果たしていますが、その理由はL1正則化を用いるといくつかの重みパラメータが0になり、重みパラメータの値が0になることで、特徴量の値も0になっているため不要な特徴量を削ることができます。ラッソ回帰は多くの説明変数の係数が0となる(スパース性を持つ)ため、リッジ回帰と比べてより強い過学習防止効果が得られます。ラッソ回帰は、説明変数の数 > 学習データ数では有効に機能しませんが、今回はこの条件は余裕で満たしています。
Lassoにも複雑さの度合いを制御するパラメータalphaがあります。alphaのデフォルトは1.0で、リッジ回帰と同じように小さくするほど複雑なモデルになります。
ラッソ回帰モデルは、sckit-learnのsklearn.linear_model.Lassoクラスで実装できますが、本記事では複数の正則化の強度を実行できるLassoCVクラスを使ってみます。
from sklearn.linear_model import LassoCV
# ラッソ回帰モデルで推定する
# L1正則化項を4パターンで試す
model_lasso = LassoCV(
alphas = [1, 0.1, 0.001, 0.0005]).fit(X_train, y)
print('Lasso regression RMSE loss:') # クロスバリデーションによる
print(rmse_cv(model_lasso)) # RMSEを出力
print('Average loss:', rmse_cv(model_lasso).mean()) # RMSEの平均を出力
print('Minimum loss:', rmse_cv(model_lasso).min()) # RMSEの最小値を出力
print('Best alpha :', model_lasso.alpha_) # 採用されたalpha値を出力
ラッソ回帰とリッジ回帰の使い分けのですが、過学習を防ぐために、使用する特徴量が減っても良い場合はラッソ回帰、過学習を防ぎたいが、使用する特徴量が全て重要な場合はリッジ回帰を選択すると良いです。
またRidgeとLassoのペナルティを組合せたものとしてElasticNetがあります。ElasticNetは多くの線形手法(線形回帰、Ridge、Lasso)を内包しているため、線形手法の中でも汎用性が高く、有力な選択肢となりますが、チューニングすべきパラメータが増えるという欠点もあるため、本記事では扱いません。
GBDT(勾配ブースティング木)
GBDTとは、学習アルゴリズムにあまり高度なものを使わず、その代わりに予測値の誤差を、新しく作成したアルゴリズムが次々に引き継ぎながら、誤差を小さくしていく手法のことです。
機械学習では、ランダムフォレストがよくアルゴリズムとして用いられます。ランダムフォレストとは、例えば、3つの決定木(学習器)があれば、それを一斉に実行して、多数決で予測値を決めます。これに対してGBDTは、決定木が増えるに従って、その決定木が持つ誤差を小さくしていく考え方です。
GBDTの実装
GBDTは、XGBoost、LightGBM、CatBoostなどのライブラリで提供されているので、それぞれインポートして使えます。本記事では、XGBoostを使いますが、Learning API版とscikit-LearnのAPI版の2種類があるので、検証とモデル作成用においてそれぞれ使うことにします。
Learning API
まずは、決定木の数を多めにして損失の推移を確かめたいので、Learning APIのxgboost.cv()を使ってみます。このメソッドは、XGboost本体であるxgboostオブジェクトを使って、クロスバリュエーションを用いた検証を行い、履歴を戻り値として返します。
決定木の深さを5、学習率を0.1にして学習してみます。決定木の数は1000にしておいて、アーリーストッピングにより制御します。
# Learning APIのXGBoostモデルで使用される、データオブジェクトDMatrixを生成する
dtrain = xgb.DMatrix(X_train, label = y)
#dtest = xgb.DMatrix(X_test)
# 決定木の深さ5、(3~9の間で1刻みで設定。5から試してみるといい。)
#学習率0.1
params = {"max_depth":5, "eta":0.1}
# xgboostモデルでクロスバリデーションを実行
cross_val = xgb.cv(
params,
dtrain, # トレーニングされるデータ
num_boost_round=1000, # 決定木の本数
early_stopping_rounds=50) # アーリーストッピングの監視回数(一般的に50程度が良いとされている)
cross_val
出力結果
# 30回以降の検証データと訓練データのRMSEをグラフにする
plt.figure(figsize=(8, 6)) # 描画エリアのサイズ
plt.plot(cross_val.loc[30:,["test-rmse-mean", "train-rmse-mean"]])
plt.grid() # グリッド表示
plt.xlabel('num_boost_round')
plt.ylabel('RMSE')
plt.show()
scikit-Learn API
アーリーストッピングが効いて、決定木が410のところで停止しました。scikit-LearnのXGBoost実装であるXGBModel()で、決定木の数を242、決定木の深さを5、学習率を0.1に設定してモデルを作成し、fit()で学習させてみます。
# xgboostで学習する
model_xgb = xgb.XGBRegressor(
n_estimators=242, # 決定木の本数
max_depth=5, # 決定木の深さ
learning_rate=0.1) # 学習率0.1
model_xgb.fit(X_train, y)
print('xgboost RMSE loss:')
print(rmse_cv(model_xgb).mean())
アンサンブル
これまでに、リッジ回帰モデル、ラッソ回帰モデル、GBDTそれぞれで、学習してきました。この結果を受け、損失の低かったラッソ回帰とGBDTを採用することにして、それぞれでテストデータを用いた予測を行うことにします。
ラッソ回帰もGBDTどちらも、predict()メソッドで予測できます。ただし、SalePriceは対数変換してから学習しているので、予測する際には対数変換前の値に戻さなければいけません。これには、NumPyのexp()メソッドを使うことにします。
lasso_preds = np.exp(model_lasso.predict(X_test))
xgb_preds = np.exp(model_xgb.predict(X_test))
予測が完了したらそれぞれの結果をアンサンブルして最終結果を決定します。損失の低さに応じて重み付き平均でアンサンブルすることにし、ラッソ回帰を0.7、GBDTを0.3にしてアンサンブルします。
preds = lasso_preds*0.7 + xgb_preds*0.3
提出用csvを作成
SalePriceの予想データをCSVファイルにまとめます。
solution = pd.DataFrame({"id":test.Id, "SalePrice":preds})
solution.to_csv("ridge_sol.csv", index = False)